Textmining
Part-of-Speech Tagging Text
Keypoints:
- We can use a NLTK’s part-of-speech tagger,
averaged_perceptron_tagger, to label each word with part of speech, tense, number, (plural/singular) and case. - We can extract all nouns from a corpus both plural (NNS) and singular (NN).
- We can visualise the nouns from a corpus using a plot of frequence distribution and a word cloud. We can do the same for other POS.
In text mining it can be useful to extract words that have a particular part of speech (POS) such as a noun or a verb. For example extracting all proper nouns can give us names and locations. This is done using a POS-tagger. The POS-tag of a word is a label of the word indicating its part of speech as well as grammatical categories such as tense, number (plural/singular) and case. POS tagging is the process of automatically determining the POS-tags of the tokens in a corpus. You can read more about the algorithm behind POS-tagging in the NLTK textbook.
In this lesson, we will use NLTK’s averaged_perceptron_tagger as the POS-tagger. It uses the perceptron algorithm to predict which POS-tag is most likely given the word. We need to download the tagger in order to use it.
The POS-tagger outputs tokens tagged with their POS-tag. It uses the Penn Treebank POS tagset which is widely used for POS-tagging text.
POS-tagging text is very useful when analysing a corpus or document and will allow us to do more indepth analysis and visualisations. In order to pos-tag using NLTK, you also have to import pos_tag from the tag package.
We are going to use the text from the US Presidential Inaugaral speeches.
nltk.download('averaged_perceptron_tagger')
from nltk.tag import pos_tag
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /Users/<USERNAME>/nltk_data...
This corpus comes in raw format but also pre-tokenised. Therefore we can call the words() method to retrieve the tokenised text of all speeches.
inaugural_tokens=inaugural.words()
print(inaugural_tokens)
['Fellow', '-', 'Citizens', 'of', 'the', 'Senate', ...]
We can assign POS-tags to all speeches using NLTK’s pos_tag() method and view the first 20:
tagged_inaugural_tokens = nltk.pos_tag(inaugural_tokens)
tagged_inaugural_tokens[:20]
[('Fellow', 'NNP'),
('-', ':'),
('Citizens', 'NNS'),
('of', 'IN'),
('the', 'DT'),
('Senate', 'NNP'),
('and', 'CC'),
('of', 'IN'),
('the', 'DT'),
('House', 'NNP'),
('of', 'IN'),
('Representatives', 'NNPS'),
(':', ':'),
('Among', 'IN'),
('the', 'DT'),
('vicissitudes', 'NNS'),
('incident', 'NN'),
('to', 'TO'),
('life', 'NN'),
('no', 'DT')]
We can then set up lists to hold specific parts of speech such as nouns. Firstly we set up an empty list and then we search for the nouns, NN singular and NNS plural. We can then print the first 20:
nouns = []
nouns = [word for (word, pos) in tagged_inaugural_tokens if (pos == 'NN' or pos == 'NNS')]
nouns[:20]
['Citizens',
'vicissitudes',
'incident',
'life',
'event',
'anxieties',
'notification',
'order',
'day',
'month',
'hand',
'Country',
'voice',
'veneration',
'love',
'retreat',
'predilection',
'flattering',
'hopes',
'decision']
Now that we have created this list of nouns, we can plot their counts in the corpus as we did earlier (see lesson on frequency counts).
from nltk.probability import FreqDist
fdist = FreqDist(nouns)
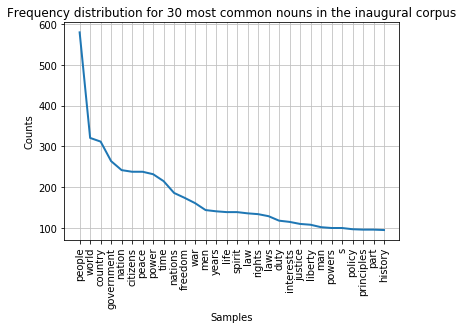
fdist.plot(30,title='Frequency distribution for 30 most common nouns in the inaugural corpus')
We can also plot the nouns as a word cloud like we did earlier (see lesson on counting tokens in text):
from wordcloud import WordCloud
%matplotlib inline
import matplotlib.pyplot as plt
cloud = WordCloud(max_font_size=60,colormap="hsv").generate(' '.join(nouns))
plt.rcParams["figure.figsize"] = (16,12)
plt.imshow(cloud, interpolation='bilinear')
plt.axis('off')
plt.show()
Task 1: Change the code above to create a frequency list for the most common adjectives in the inaugural corpus.
The POS-tag for adjective ‘JJ’.
Answer
adjectives = [] adjectives = [word for (word, pos) in tagged_inaugural_tokens if (pos == 'JJ')] adjectives[:20]
Task 2: Plot a word cloud of the adjectives in the inaugural corpus.
Answer
import matplotlib.pyplot as plt cloud = WordCloud(max_font_size=60,colormap="hsv").generate(' '.join(adjectives)) plt.rcParams["figure.figsize"] = (16,12) plt.imshow(cloud, interpolation='bilinear') plt.axis('off') plt.show()
Task 3: You can do the same for another POS-tag.
For the full list of Penn Treebank POS tags see here.
Answer
adverbs = [] adverbs = [word for (word, pos) in tagged_inaugural_tokens if (pos == 'RB')] adverbs[:20] import matplotlib.pyplot as plt cloud = WordCloud(max_font_size=60,colormap="hsv").generate(' '.join(adverbs)) plt.rcParams["figure.figsize"] = (16,12) plt.imshow(cloud, interpolation='bilinear') plt.axis('off') plt.show()
Task 4: You can look at the tokens and tagged tokens of individual inaugurals using the fileids() method.
We find the tokens of Biden’s inaugural and Trump’s inaugural, for instace, with the fileids() method, beginning with the most recent, as follows:
inaugural_tokens_biden = inaugural.words(inaugural.fileids()[0:-1])inaugural_tokens_trump = inaugural.words(inaugural.fileids()[1:-2])You can sample slices from the two inaugurals as follows:
inaugural_tokens_biden[55:95]inaugural_tokens_trump[55:95]We can look at their tagged tokens like this:
tagged_inaugural_tokens_biden = nltk.pos_tag(inaugural_tokens_biden) tagged_inaugural_tokens_biden[:20]tagged_inaugural_tokens_trump = nltk.pos_tag(inaugural_tokens_trump) tagged_inaugural_tokens_trump[:20]Now you can search for nouns, adjectives, and adverbs in the inaugurals of Biden and Trump separately, and any other inaugural you’d like to look at, the way we have done for the inaugurals as a whole.
EXTRA: Tasks on inaugural text corpus that incorporate tools from previous lessons - Define and text mine the speeches of Biden, Trump, Kennedy, or any other inaugural speech.
Define individual inaugural speeches using the
Textclass function of the NLTK package (confer with course section on concordances). For example:biden = nltk.Text(inaugural.words('2021-Biden.txt'))When you have defined an inaugural, you can search for concordances, collocations, and count for lexical diversity in it. See full description of
Textclass functionality at NLTK.Do concordances in the defined inaugural speeches on these terms: “democracy”, “america”, “freedom”.
What other words appear in a similar range of contexts as these terms? We can find out by appending the term similar to the name of the text in question, then inserting the relevant word in parentheses (confer with the NLTK textbook). Search for words that also appear in the context of some of these terms (“democracy”, “america”, “freedom”).
Search for collocations in each speech.
Measuring things: Count vocabulary and unique vocabulary items. Measure the lexical richness, identify long words and find their frequency distributions. You can see the example code to follow in the NLTK textbook.
Compare the results from your searches. Are there any striking findings?